I am looking for a fulltime engineer and PhD position now. I have just finished a year of research intern in UISEE(Nanjing) AI Center under the supervision of Prof. Jianbo Shi. The work was mainly focused on high-level vision tasks like tracking (SOT and MOT) and relative navigation. Before that, I have received my Master degree in Computer Vision from Beijing Institue of technology advised by Prof. Yunde Jia and Prof. Yuwei Wu . My master thesis is mainly focused on the low-level vision tasks like stereo matching and monocular depth estimation. I received my Bachelor degree in Computer Science from the Ocean University of China.
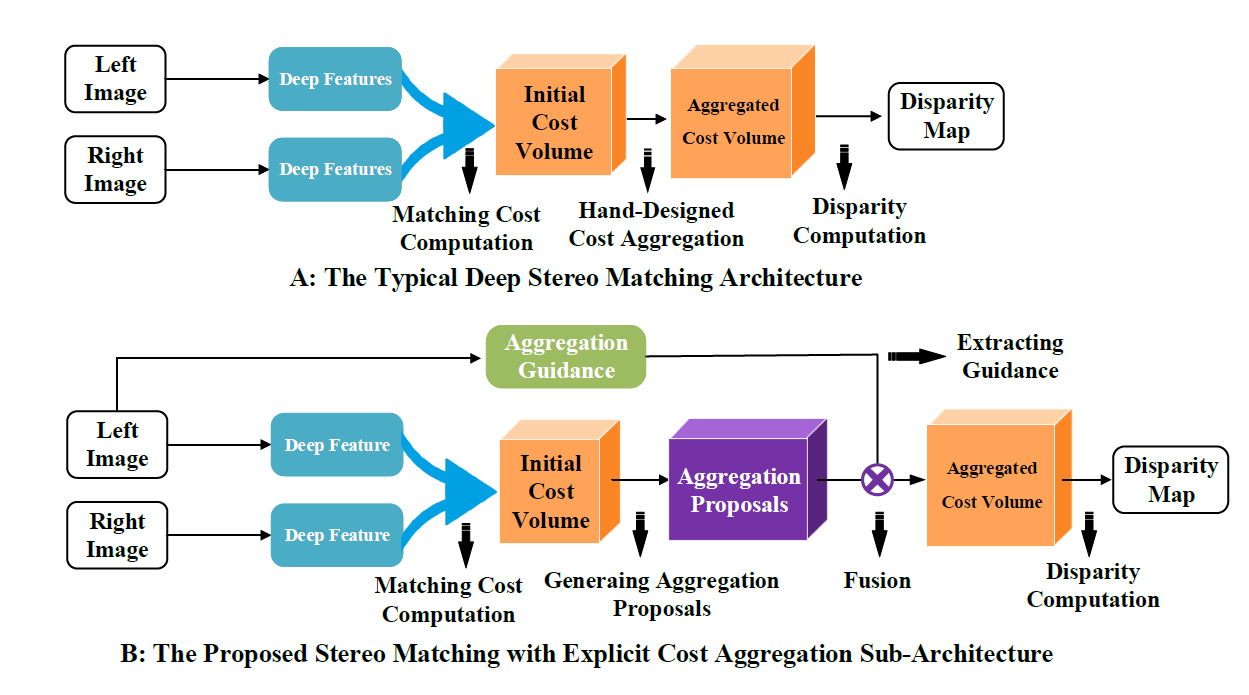
We propose to use the low-level feature map, which contains rich geometry information like edges and silhouettes to guide the cost aggregation.
Stereo Matching, Cost Aggregation, Interpretable Guidance
Current deep stereo matching lacks interpretable cost aggregation
Overpass baseline GC-Net 2.4% on EPE, reach top3 on KITTI15 in 2017 and surpass 0.7 on the foreground. The final disparity map gives better performance on details and keeps the better result on edges.
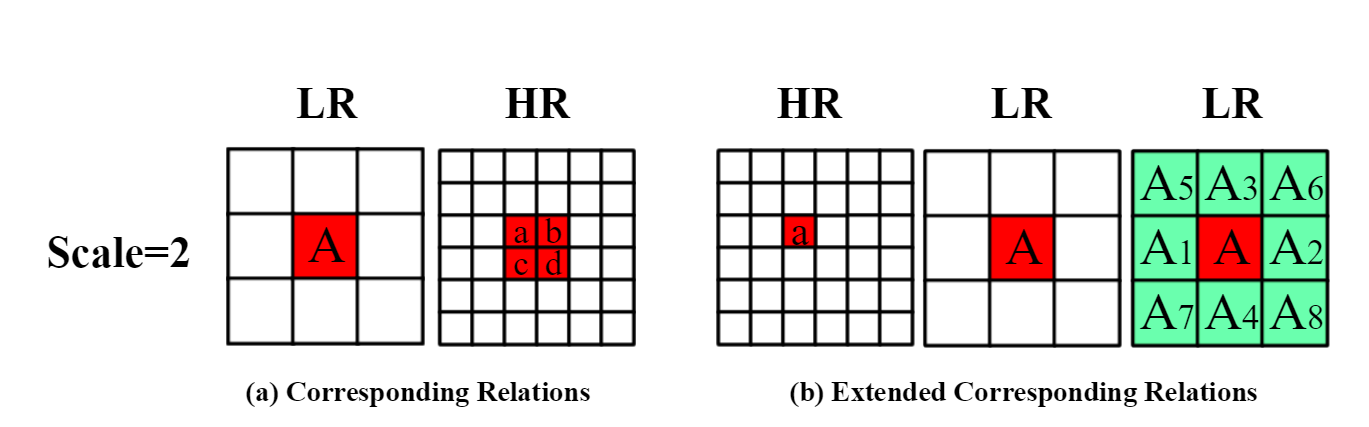
We explicitly model the mapping relation by the similarity between high-resolution (HR) and low-resolution (LR) feature maps. The mapping relation is represented by a weight matrix where each element is the similarity between corresponding HR and LR feature vectors. To map the LR matching result back to HR space, we use the computed matrix rather than use the normal up-sampling layers like bilinear interpolation or deconvolution.
Stereo Matching, Up-Sampling, Bottleneck module
The sub-sampling operation provides the feature with a large receptive field, but it also brings the loss of details like silhouettes. Using skip-connection can maintain the details, but it is hard to interpret how the high-level features refine the low-level matching result.
Our method gets a SOTA result with 0.59 EPE on the SceneFlow dataset, where the baseline PSM only gets 1.09 on EPE. The results on KITTI is just comparable because the sparse supervision is not supportive to learn the mapping matrix by backward propagation.
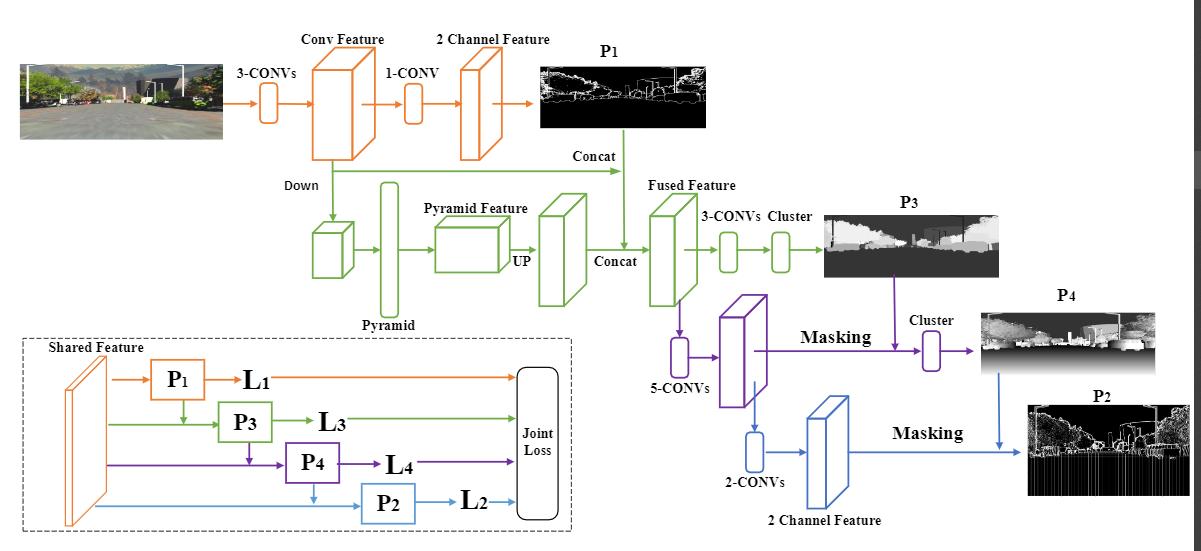
We propose the region support knowledge as guidance to regularize the deep stereo matching. The region support knowledge, P, consists of four kinds of prior knowledge, where P1 is the discriminative region supports, P2 is the representative pixel sets, P3 is the object-level segmentation, and P4 is the plane-level segmentation.
Stereo Matching, interpretable network, regional guidance, guided learning
Current deep stereo matching methods are mostly built in a black box and lack of interpretability. To build a reliable stereo matching pipeline, we argue that it is essential to design the network in an explainable manner.
The final stereo matching method outperforms baseline GCNet on SceneFlow and KITTI datasets by applying the region support for all three steps. On Sceneflow, it is four times faster than the baseline and gets 0.2 promotion on EPE. On KITTI15, it gets 2.34 for all pixels error, which is 0.5 higher than GCNet.
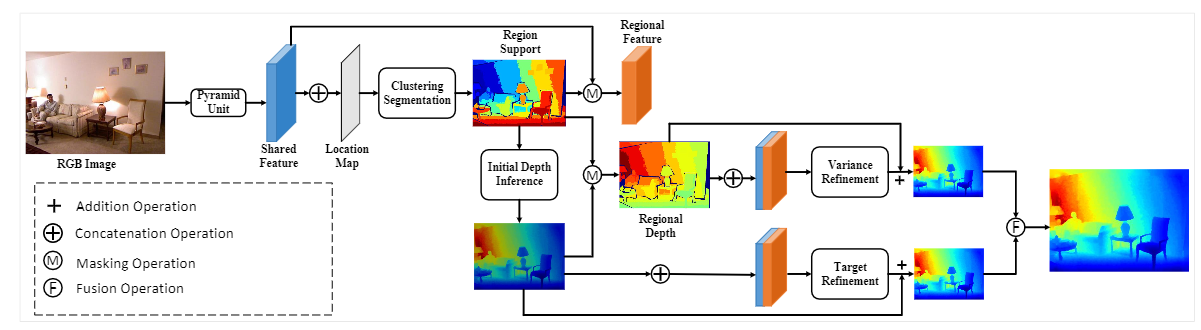
We propose a new depth estimation method using region support as the inference guidance and design a region support network to realize the depth inference.
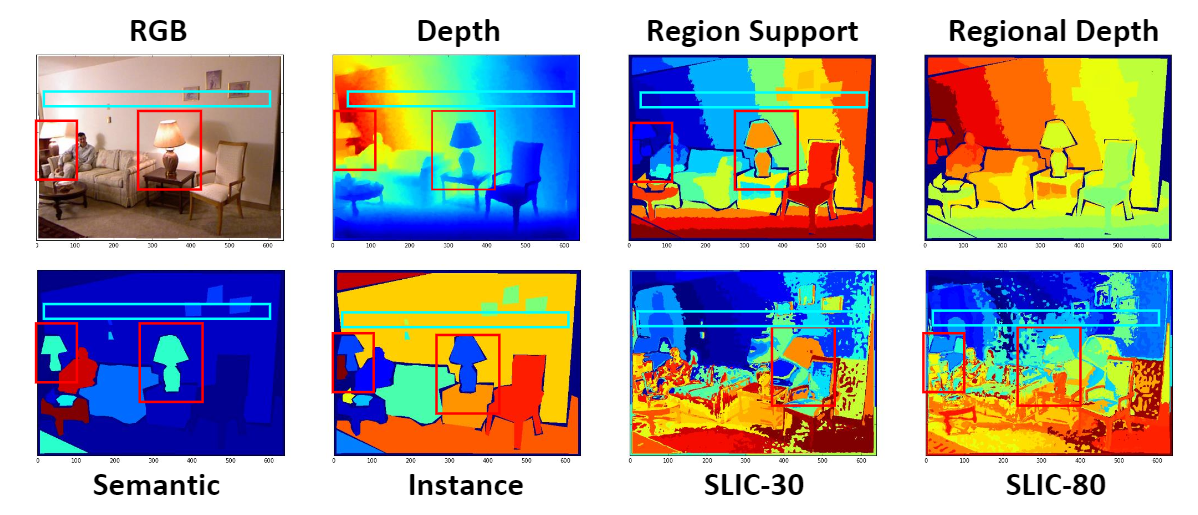
Monocular Depth Estimation, Auxiliarty Loss, Multi-Task learning
Monocular depth estimation mostly relies on monocular cues like the scale ratio, feature variance of objects, and so on, but these cues are ambiguous to guide the depth inference. Regional guidance, like semantic segmentation, helps resolve the ambiguity. But in many situations, the semantic guidance has a conflict with depth distribution.
The region support network finally runs in an end-to-end manner by seamlessly integrating two modules. Our method reaches SOTA performance on the NYU dataset with the region support, which outperforms the baseline 0.1 (coarse) and 0.3 (fine) on RMSE-linear.
We introduce a fog volume representation to collect these depth hints from the fog. We construct the fog volume by stacking images rendered with depths computed from disparity candidates that are also used to build the cost volume. We fuse the fog volume with cost volume to rectify the ambiguous matching caused by fog.
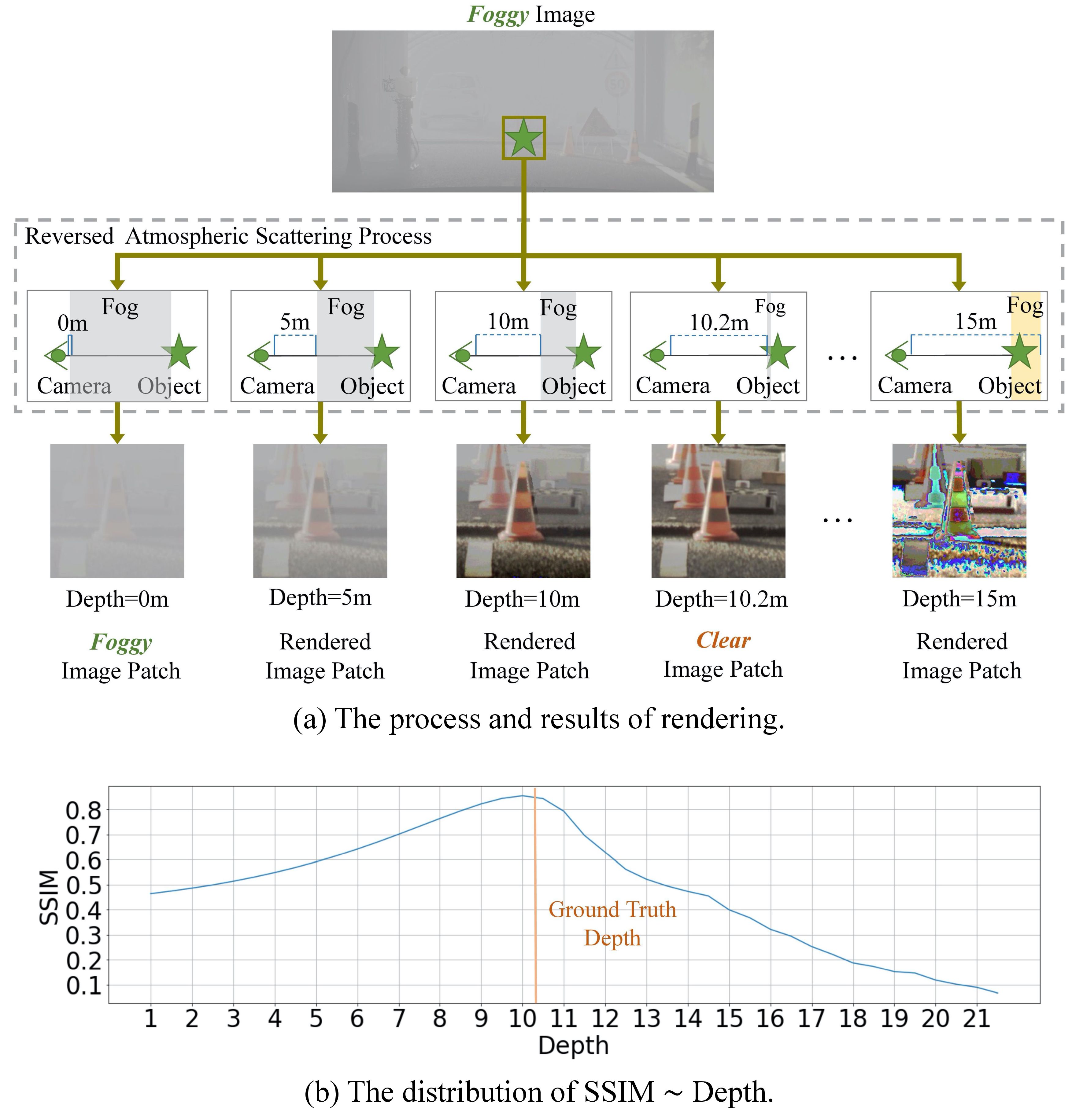
Stereo Matching, Defog Rendering, Iterative Refinement, Noise as Feature
Stereo matching in foggy scenes is challenging as the scattering effect of fog blurs the image and makes the matching ambiguous. Prior methods deem the fog as noise and discard it before matching. Different from them, we propose to explore depth hints from fog and improve stereo matching via these hints. The exploration of depth hints is designed from the perspective of rendering. The rendering is conducted by reversing the atmospheric scattering process and removing the fog within a selected depth range. The quality of the rendered image reflects the correctness of the selected depth, as the closer it is to the real depth, the clearer the rendered image is. We introduce a fog volume representation to collect these depth hints from the fog. We construct the fog volume by stacking images rendered with depths computed from disparity candidates that are also used to build the cost volume.
Experiments show that our fog volume representation significantly promotes the SOTA result on foggy scenes by 10% to 30% while maintaining a comparable performance in clear scenes.
We leverage the imitation learning method and directly learn the driving behavior from collected data. We implement the world model, GAIL, and InfoGail as the baseline and add a prediction module to get a more stable result.
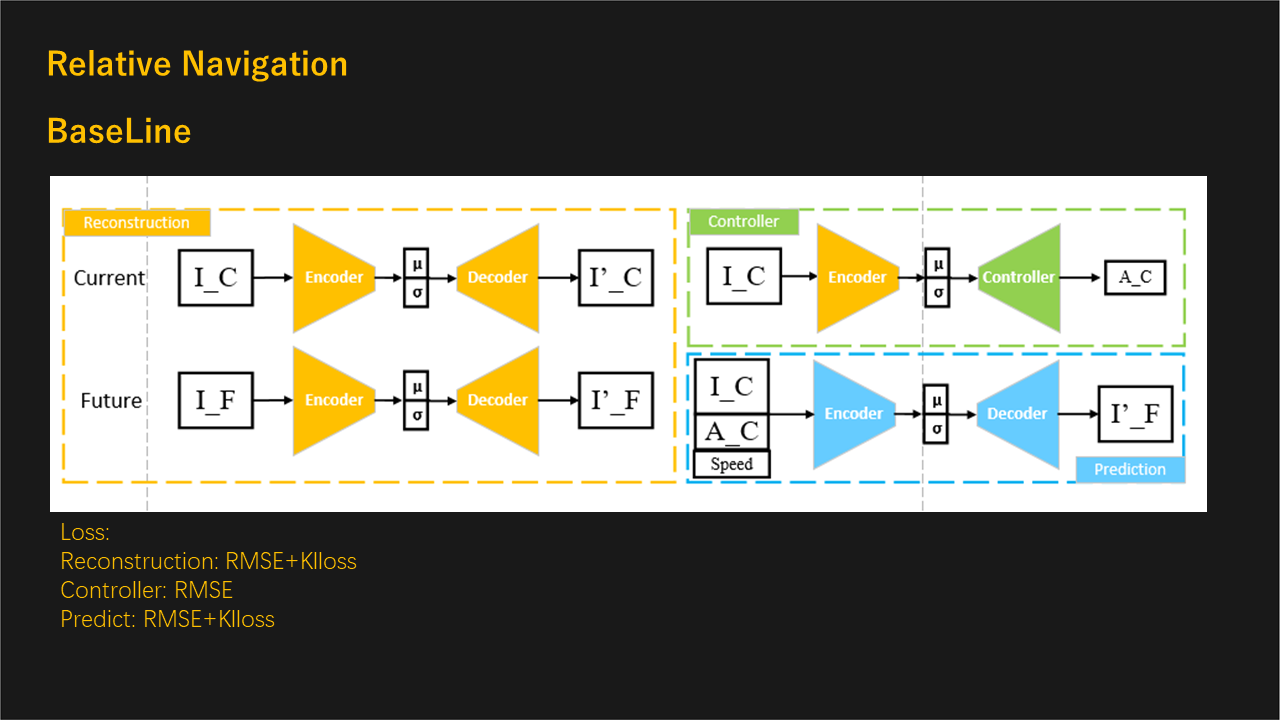
Imitation Learning, Relative Navigation, Action Prediction, Cross-modal Inference
Build a learnable controller for an autonomous driving system and realize the relative navigation of cars.
Our method gives a driving score of 970 on the GYM platform, which surpasses most reinforcement learning methods. The action prediction module is successfully employed on real cars, which navigate in the closed roads.
We propose to distangle the foreground information from the extracted feature and use it for the correlation operation.
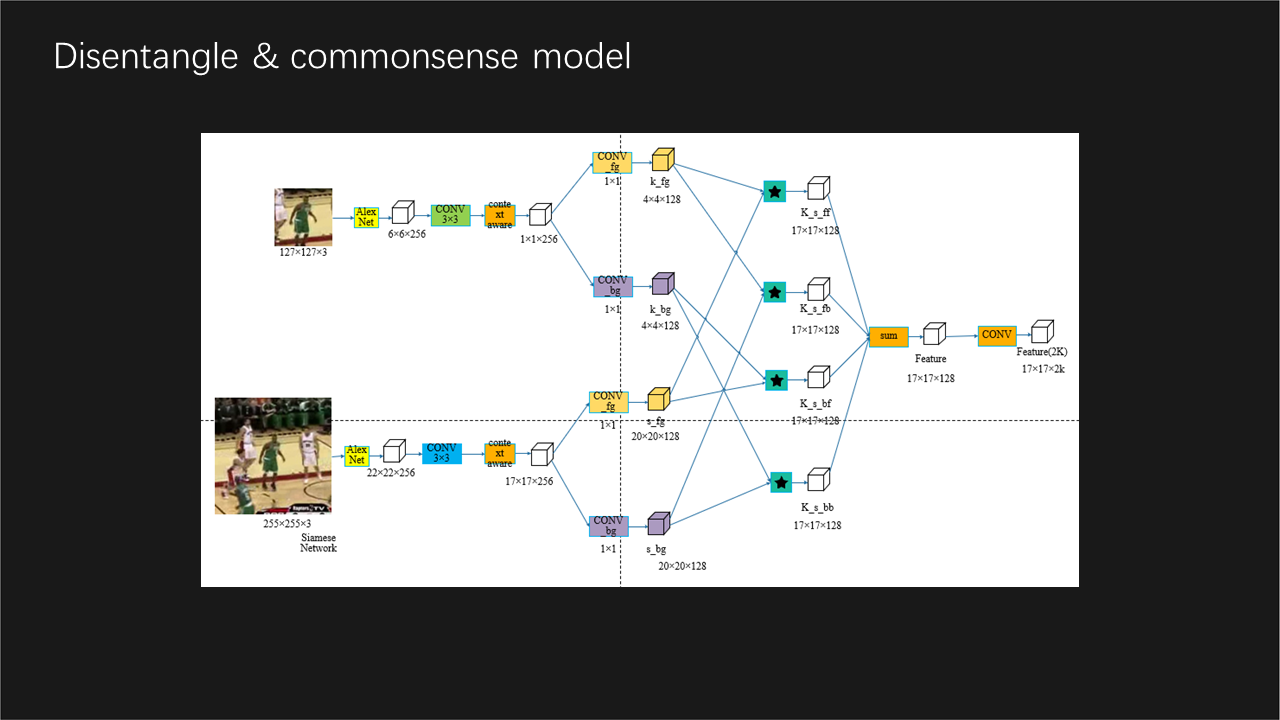
Single Object Detection, Feature Distanglement, Capsule, GAN
The correlation based matching is effective for SOT, but the feature are fused with background information, which makes the feature less discriminative for the matching
We get comparable result to the PYSOT where the accuracy is 0.389 on OTB100, 0.549 on VOT. Our method gets a more stable performance on long-term video and is robust to the camera vibration.
We propose to use the deformation convolution network to predict the deformation between two images and connect the detection results.
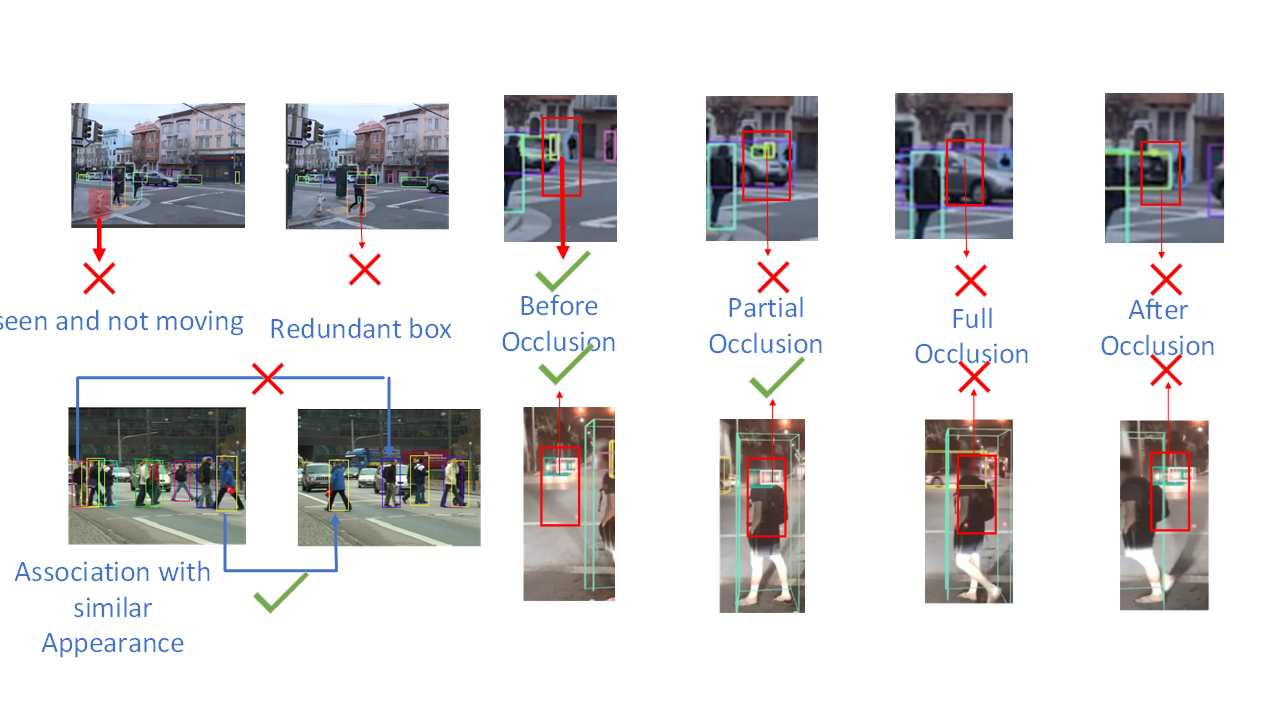
Multiple Object Detection, Deformable Convolution
We aim to use deformable convolution to learn the relative deformation between two images. We warp the detection results on the T-1 frame to the T frame with the deformation and connect them with the detection result on the T frame.
On KITTI, we get a much higher accuracy for the vehicle, which is 0.752 compared to the baseline (without video aggregation) 0.419. As for the pedestrian, we get 0.817 compared to the baseline 0.356. With video aggregation, we only detect 60% of the bbox of the baseline. Although the recall comes down, we can add the sampling frame and connect most of the frames.
We propose to use the deformation convolution network to predict the deformation between two images and connect the detection results.
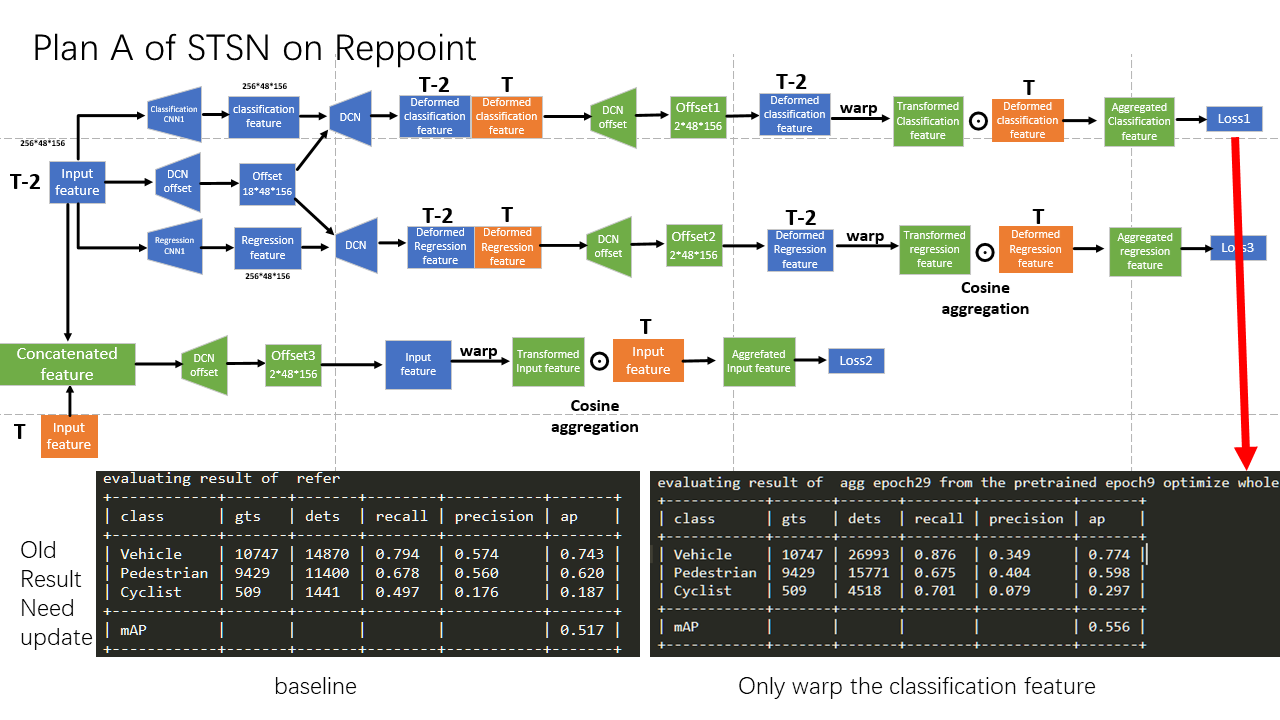
Video Object Detection, Deformable Convolution, Temporal Aggregation
Due to the occlusion and blurring, the object is hard to be detected as the feature is not damaged. We aim to bring supportive information from related frames to enhance the feature of the current frame.
Our final result uses the RepPoint as the baseline and adds a mask on the deformable convolution layer. On KITTI, our AP is 0.628, which is 12$ higher than the baseline 0.560. On Waymo, our method gets AP of 0.663 compared to the baseline of 0.626.
