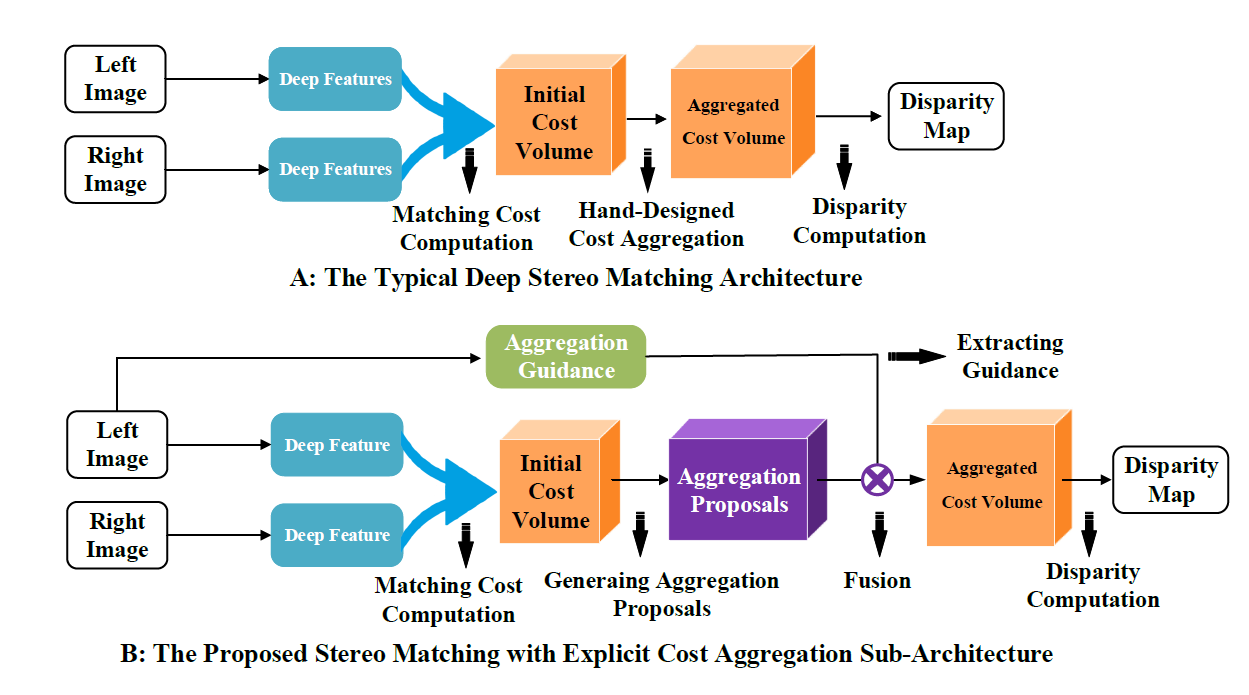
Deep Stereo Matching with Explicit Cost Aggregation Sub-Architecture
Abstract
Deep neural networks have shown excellent performance for stereo matching. Many efforts focus on the feature extraction and similarity measurement of the matching cost computation step, while less attention is paid on cost aggregation, which is crucial for stereo matching. This paper presents a learning-based cost aggregation method for stereo matching by a novel sub-architecture in the end-to-end trainable pipeline. We reformulate the cost aggregation as a learning process of the generation and selection of cost aggregation proposals, which indicate the possible cost aggregation results. The cost aggregation sub-architecture is realized by a two-stream network: one for the generation of cost aggregation proposals, the other for selecting the proposals. The criterion for the selection is determined by the low-level structure information obtained from a light convolutional network. The two-stream network offers global view guidance for the cost aggregation to rectify the mismatching value stemming from the limited view of the matching cost computation. The comprehensive experiments on challenge datasets such as KITTI and SceneFlow show that our method outperforms state-of-the-art methods.
Problem
The deep stereo matching methods lack the interpretability during cost aggregation. Only using 3D convolution without any guidance makes the cost aggregation process unexplainable and hard to balance the smoothness among the plane and the clear result on silhouettes.
Solution
We observe that the low-level CNN feature map has strong information on the edges. Therefore, we propose to use this information to guide the cost aggregation process, where the 3D convolution can both leverage the high-level semantic information of the later layers and low-level geometrical information from the first feature layers. As a result, the network can learn to balance the performance on edge and among the plane, referring to the different signal correspondences of the high-level and low-level feature maps.
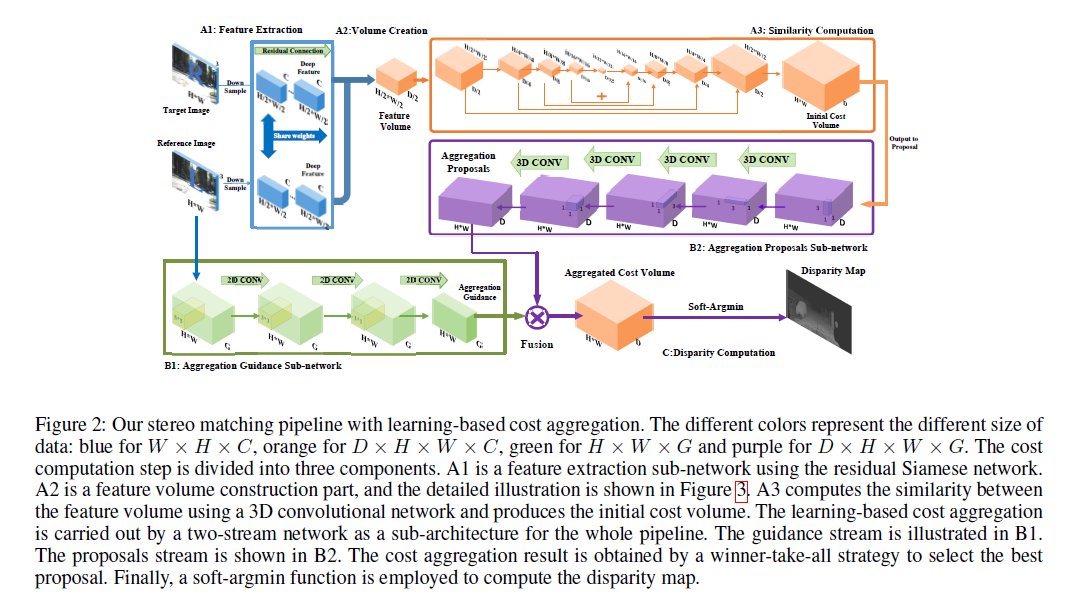
The below figure shows the details of the network. Two branches are designed:
1. We generate the aggregation proposals from the obtained 3D feature map, which is an implicit 4D feature map by CDHW. The proposals is a 5D feature map as KCDHW, where K is the number of the proposals.
2. We reuse the feature map from the previous 2D CNN as the guidance to select or fuse the proposals as the final aggregation result.
Result
The proposed architecture outperforms the baseline GCNet on the Scene Flow and the KITTI benchmarks.
The left figure shows our results on the KITTI dataset, where the proposed method can simply improve the result of the baseline GCNet.

The right figure shows the obtained guidance and its influence on the final result. To get a better visualization result, we pre-compute the mask only with the ground truth depth. The feature map is computed through the threshold of the mean value fo the feature map, so we can easily see the strong signal on the feature map. We also apply the gradient check on the mask, where we can see a division on the top of the illustration result. This operation is to check the relation between the guidance and the depth gradient.