Region-Support Depth Inference from a Single Image
Abstract
Depth inference from a single image is a long-standing problem in the computer vision community. It is technically ill-posed since monocular cues are ambiguous for the depth inference. Using semantic segmentation results helps resolve some ambiguities of monocular cues, but it also introduces new ambiguities between semantic labels and depth values. To address this issue, we propose a new depth estimation method using region support as the inference guidance and design a region support network to realize the depth inference. The region support network consists of two modules: the generation module for region support and the coarse depth refinement module. The generation module employs a pyramid unit to determine the region support from the RGB image. The region support concatenates the RGB image to form the inference guidance and provides the refinement's initial coarse depth. With the inference guidance, the refinement module implements the coarse-to-fine strategy in a novel iterative manner by a simplified pyramid unit. The NYU dataset experiments demonstrate that the region support can significantly resolve the ambiguities and improve inference accuracy.
Problem
Monocular depth estimation mostly relies on monocular cues like the scale ratio, feature variance of objects, and so on, but these cues are ambiguous to guide the depth inference. Many strategies have been proposed to resolve the ambiguous problem, such as using the additional supportive guidance like semantic information to guide the inference, discretizing the continuous depth into interval values to regularize the inference space, using the coarse-to-fine framework to arrange the inference, and so on.
Many methods especially find that it is profitable to combine the depth estimation with the semantic segmentation using multi-task neural networks, where neural networks effectively leverage the semantic information to guide the depth inference. However, there are still many ambiguous situations where semantic guidance is not helpful. For example, when objects lying on different depths have the same semantic label, the same label is ambiguous to infer the different depth values. Besides, since the semantic labels are the same for pixels among one object, if this object strides over a large variance of depths, the same labels are also ambiguous for the depth inference.
Solution
In this work, we present a novel neural network called region support network (RSN) to carry out the depth inference with the region support. As shown in the flow Figure 1, the RSN consists of two modules: the generation of the region support and the refinement of the coarse depth. We design a new pyramid network to use multi-scale features for the determination of the region support. We gain supervision for the training from semantic segmentation results and the depth map. A new region-based loss $\mathcal{L}_{r}$ is designed to supervise the learning process. The obtained region support concatenates with original RGB images as the inference guidance for the refinement module. With this guidance, the refinement iteratively uses a simplified pyramid unit to infer the accurate depth from the coarse depth. The region support also works as the initial coarse depth, and then the later refined depth map replaces the previous coarse depth to form the new input. The region support network finally runs in an end-to-end manner by seamlessly integrating two modules. With the region support, our method reaches appealing performance on the NYU dataset. Comparing the different guidance shows that the region support can significantly resolve the ambiguities and regularize the inference space.
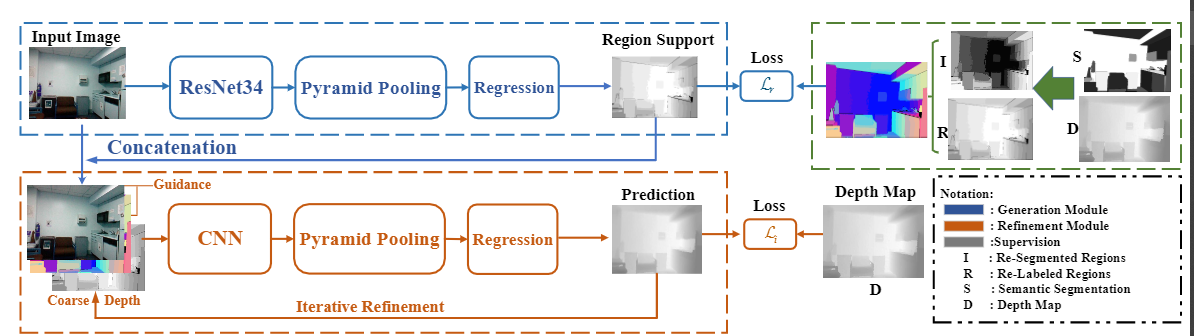
Figure 1. The region-support depth inference network. The network consists of three modules: generation of region support, computation of the regional depth, and the regional refinement. A pyramid unit provides the multi-scale feature for all of the three modules. We first use the clustering-based segmentation module to obtain the region support. Then we use the region support as additional information to support the inference of the initial pixel-wise depth. After that, we can compute regional depth and regional features using the region support as masks on the initial pixel-wise depth and shared feature maps. The regional refinement module separately works on the regional depth and the initial depth map by the variance and the target refinement. The variance refinement infers the depth by computing the variance based on each region's mean value while the target module computes the variance of depth with the target of the mean value.
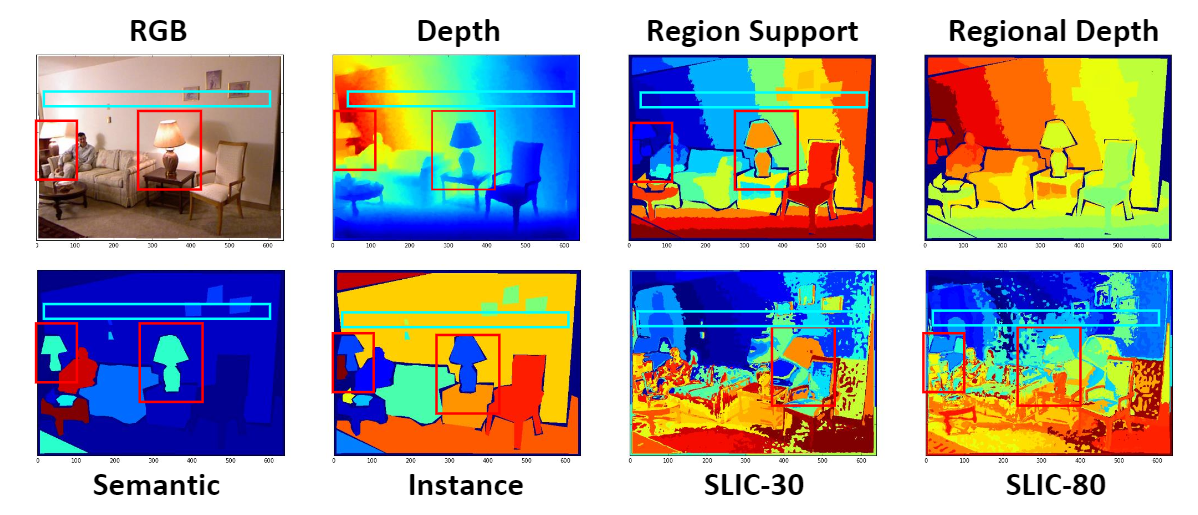
Figure 2. Illustration of region support. The region support is a special kind of segmentation of regions, consisting of pixels at similar depths. Like many regional guidances, it guides the inference by assuming that with the same regional label, the variance of depth should be stable and continuous. However, most regional guidance can not truly realize this assumption, as shown in Figure \ref{fig:comparision}. The semantic guidance has a problem in the red box where the 'lights' are at different depth but has the same semantic label. Besides, in the blue box, objects like 'wall' cross a long-range of depth, but the label is the same for the region. As for the super-pixel based approaches, the division of regions is too sensitive to adapt for different scenes. Compared with these guidelines, the region support can effectively handle the above ambiguous situations.
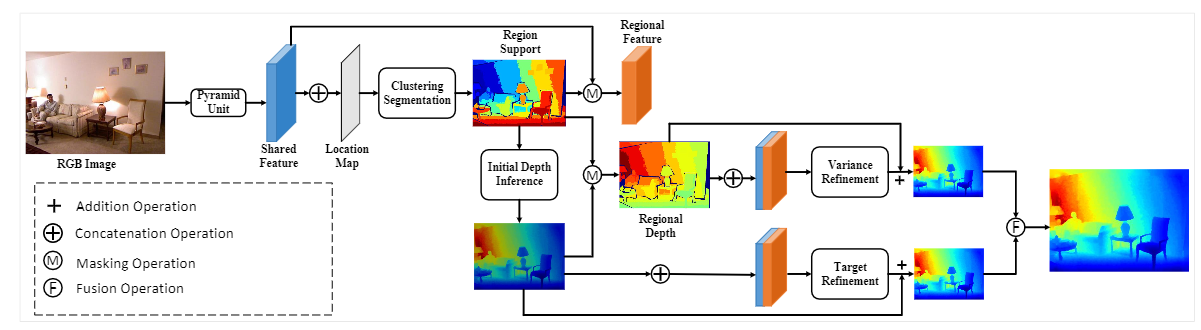
Figure 3. The overview of our depth estimation method. The generation module uses a pyramid-based architecture to generate the region support, as shown in the blues legend. The supervision of region support is obtained from the segmentation results, and depth map, as shown in the green legend and a region-based loss function $\mathcal{L}_{r}$ is designed for the training. The region support concatenates with the RGB image as the inference guidance for the refinement to infer the accurate depth. The orange legend shows that the refinement carries out in an iterative manner with a simplified pyramid unit. Besides, an iterative loss $\mathcal{L}_{i}$ is designed for the training. This figure is better shown in the colorized view.
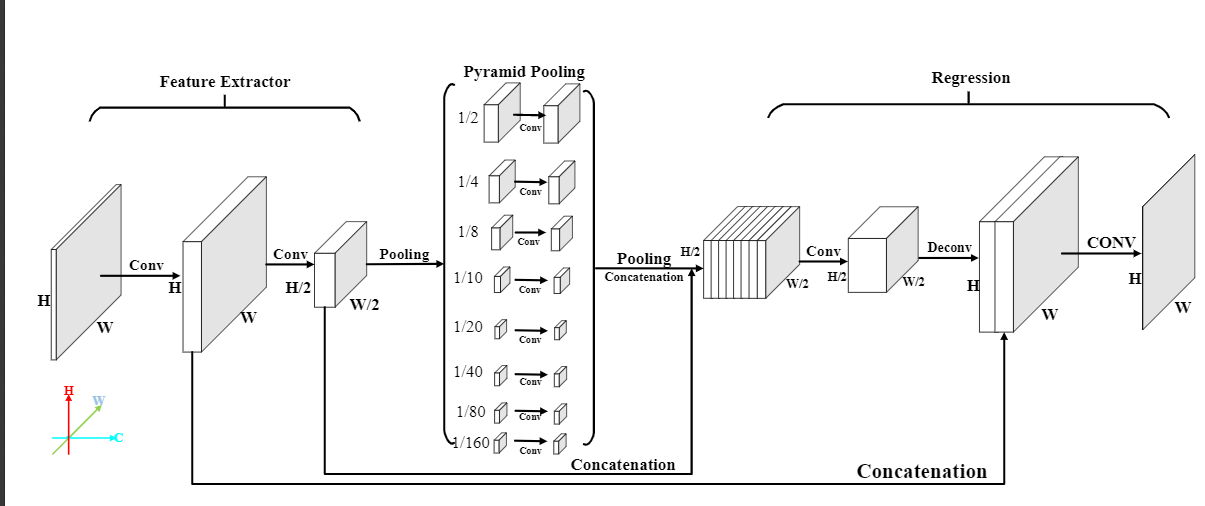
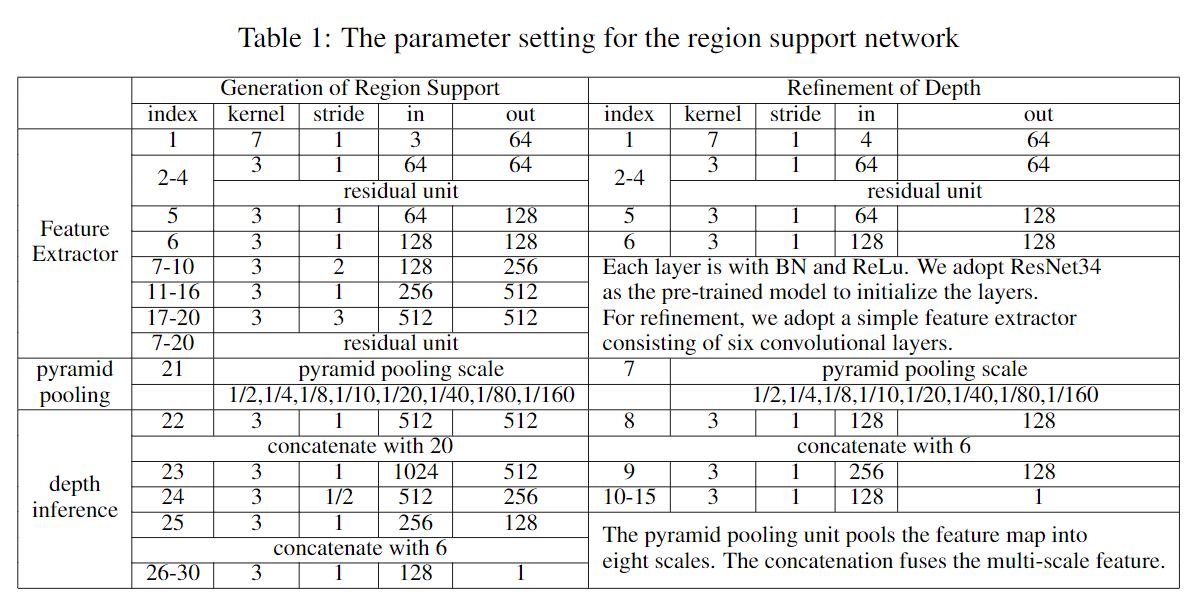
Figure 4. Network architecture. The pyramid network is used for both the generation module and the refinement module. It consists of feature extractor, pyramid pooling unit, and depth regression. The detailed layer setting is shown in Table \ref{tab:parameter}. For the generation module, a ResNet34 is employed as the feature extractor while the refinement only uses six convolutional layers. The pyramid pooling unit pools the feature map into eight scales, i.e., $1/2,1/4,1/8,1/10,1/20,1/40,1/80,1/160$ to gain the multi-scale feature. The final eight convolutional layers are employed to regress the depth value. The detailed network setting is shown in the below table

Algorithm 1 to generate the ground truth of region support from depth and image.

Algorithm 2 to compute the region support by network.
Result
Table 1. Ablation result on NYU Benchmark .
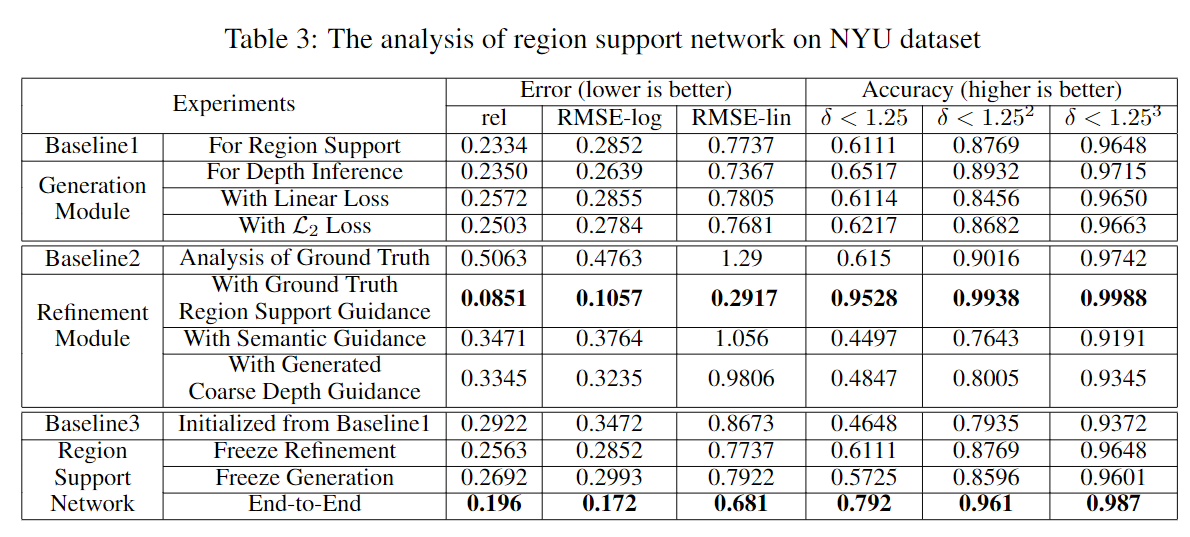
To demonstrate the effectiveness of the region support, we use the ablation analysis of the RSN. The results are shown in Table \ref{tab:analysis}. First, we focus on the generation module. The \emph{Baseline1} is the generation module trained for the region support with the log $\mathcal{L}_{r}$. Despite the validation in Table \ref{tab:analysis}, we compute the mean value of RMSE and variance among each region, according to depth map and region support, respectively, which is $0.3613$, $0.1196$ and $0.2852$, $0.117$. The results show that even though the mean value is close to the ground truth, the generated region support still has an unstable variance of more than $41\%$. The generation module for \emph{depth inference} is directly trained by log $\mathcal{L}_{r}$ loss function on the depth map to figure out the ultimate performance of our pyramid unit. After $40$ epochs, the generation module reaches $0.7367$ linear RMSE. The results show that the pyramid architecture effectively utilizes the multi-scale feature for depth inference. We test the \emph{linear loss} of $\mathcal{L}_{r}$ for the generation module. We can see that after both trained of $40$ epochs, the log loss is $6.67\%$ lower than the linear loss. But we also find the linear loss converges faster than the log loss. Only after $17$ epochs, the linear loss can reach $0.837$ RMSE. To this end, the final end-to-end RSN is first trained by linear $\mathcal{L}_{r}$ for $17$ epochs and then trained for by the log $\mathcal{L}_{r}$. The comparison of the proposed $\mathcal{L}_{r}$ loss and \emph{$\mathcal{L}_{2}$ loss} is in log space. The $5.67\%$ improvement in log RSME shows that the $\mathcal{L}_{r}$ loss is better for the depth estimation task.
Table 2. Comparison result in NYU with SOTA methods.
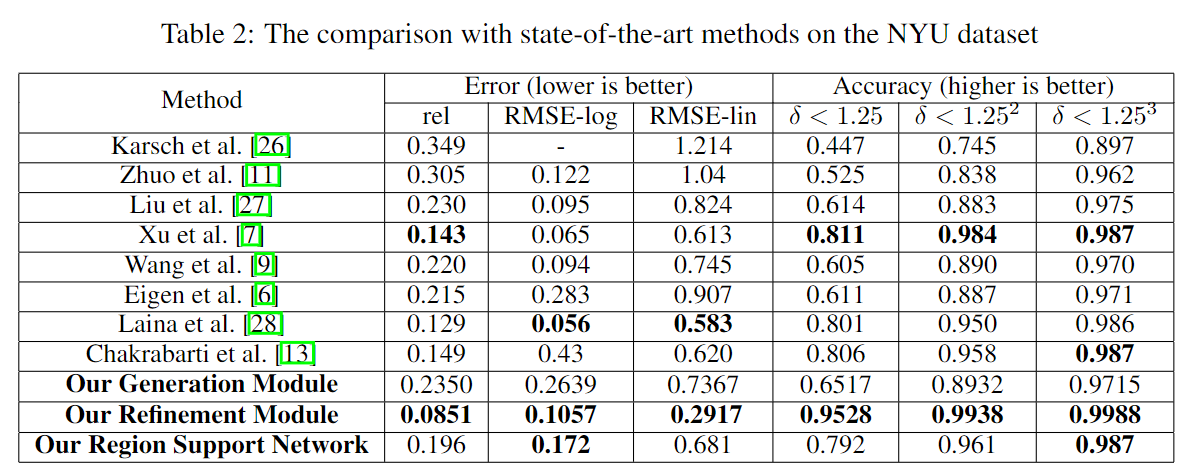
The results on the NYU dataset are shown in Table 2. The generation module and the refinement module are modified to infer the depth directly. The generation module reaches comparable results on RSME and threshold accuracy. This proves the pyramid network can capture the multi-scale feature for depth inference. The refinement module gets very impressive performance with the ground truth of region support. The region support from Algorithm \ref{alg:region} helps the refinement module significantly outperform the state-of-the-art method. Especially in RSME and related error, it outperforms more than $50\%$ than the state-of-the-art. This result demonstrates the region support is extremely instructive to resolve the ambiguities in the depth inference, and the iterative refinement effectively uses the guidance to achieve the coarse-to-fine strategy. But directly using the region support might be a little unfair for other methods. So we also combine the two modules to infer depth end-to-end. Although using the fewest training data, the final RSN still reaches a comparable performance with the state-of-the-art methods, and the threshold accuracy reaches state-of-the-art performance.\footnote{The bold log error of RSN is because the log function of log error has two class: $log_{10}$ and $log_{e}$. The 0.172 is the best $log_{e}$ result while its $log_{10}$ result is 0.112.}
Figure 4. The visualization of the computed region support.

We visualize the predicted depth map from the region support network, refinement module with ground truth region support guidance, generation module and refinement module with semantic guidance.